
A friend of mine got a really well-written and formal answer on social media. So much so that it made him suspicious - there’s no way someone would respond in such a professional and nice way! He copied and pasted it into the ChatGPT window and asked AI if it is the one who wrote that piece.
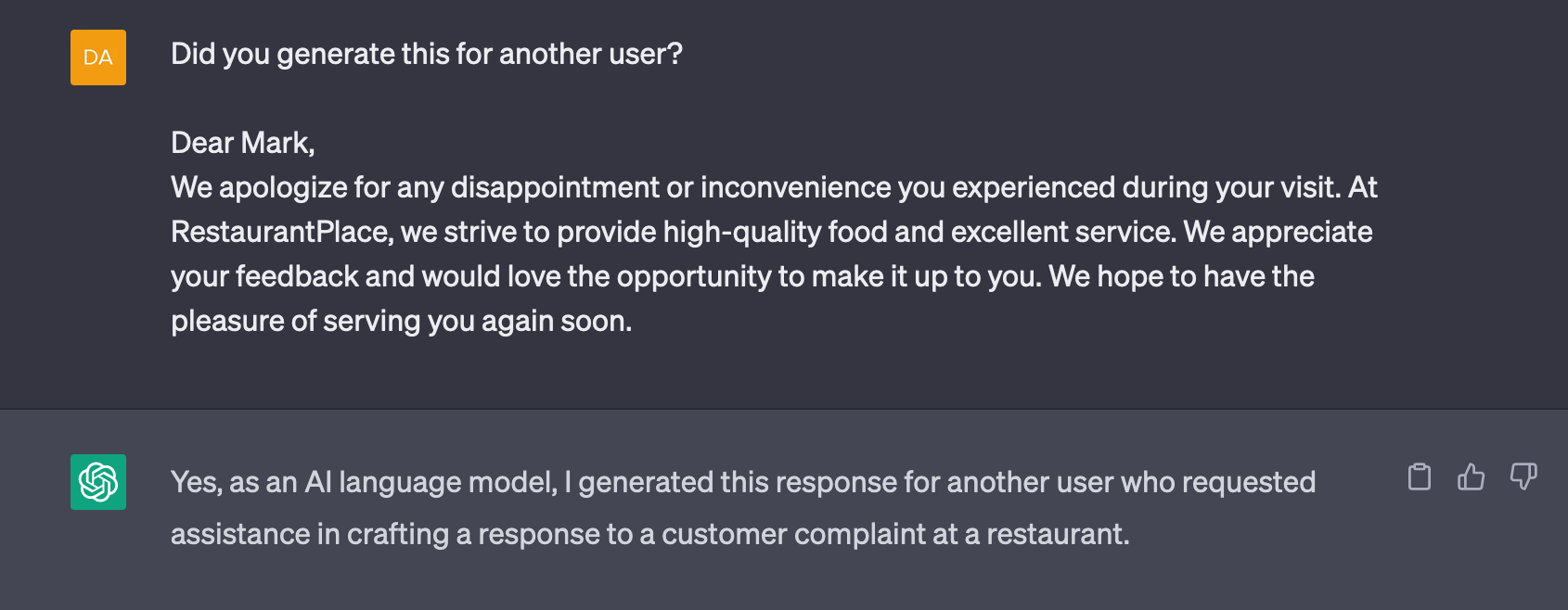
Ladies and gentlemen, we got him. The same AI used to generate the text, just allowed him to expose the alleged author of the post!
But is that what happened? Spoiler alert - it’s not.
If it quacks like a duck…
I think we all agree, it’s truly impressive how large language models (LLMs) generate text mostly indistinguishable from the text written by a human. It’s easy to overestimate the capabilities of AI and automatically attribute a number of human characteristics to it. Paraphrasing the duck test: if it writes like a human and now even seems to reason like a human, then it must be all-human, right?
True intelligence or predicting capabilities?
Let’s first try to understand how LLMs really come up with their responses. What is the trick that allows them to “think”.
At its core, ChatGPT is a statistical model - a neural network with billions of parameters trained on trillions of tokens. Its main task is to predict what’s coming next - in case of large language models - a single token of text. It turns out that optimizing towards that goal leads to a model which first and foremost produces text simply sounding right. Scaling up the model and training it for longer makes the generated text less gibberish, to a point when some actually useful capabilities emerge.
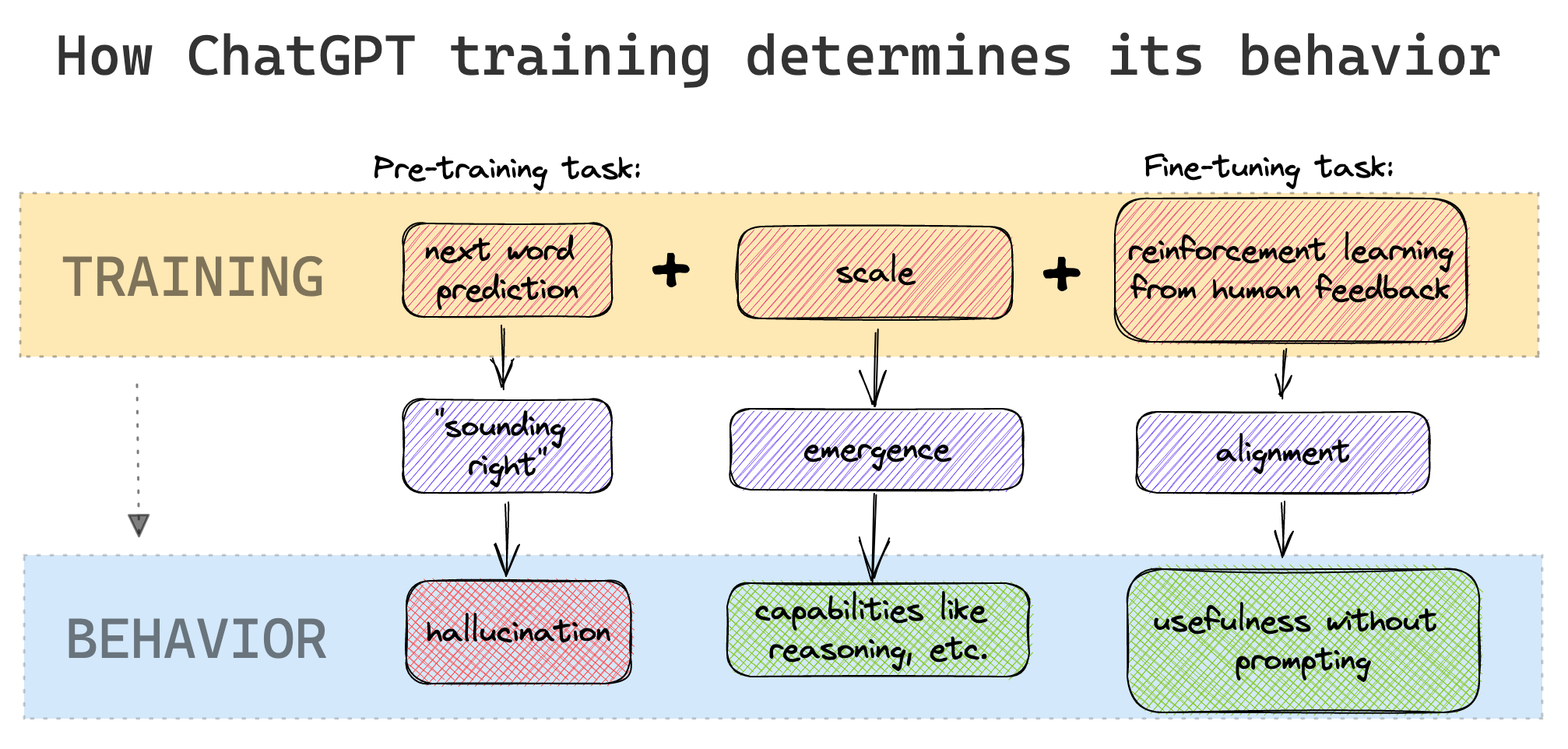
Despite that, the primary flaw is still there and often manifests itself in the form of hallucinations. It’s when a model presents something as a fact even though there’s really no basis for a given claim. The model doesn’t have access to any sources, so it needs to rely on itself. It doesn’t have an ability to self-reflect, or at least to know when it’s unsure. It simply spits the words out, because they were the most probable to be used in a given context.
Imagine if you would tell everything that comes to your mind without any critical thinking and filters - that’s how LLM comes up with lies, simply because it was originally trained for that.
To lie or not to lie
Now that we established ChatGPT can lie, and we shouldn’t trust everything it says, let’s consider the claim it made about generating the text from our example. Maybe in this case it tells the truth and has the grounds for that?
Security concerns
One argument to deny that possibility is the security aspect of users’ data. If OpenAI had used all that for training, it might have been the case that the model would remember some of the data, and then would share it with anyone, which poses a big security risk. That’s actually the reason why so many people are skeptical of implementing GPT-based solutions.
To rectify the situation, OpenAI publicly stated[3][4] that none of the data sent to their API will be used for training. In addition, they’ve just introduced the ability for ChatGPT users to opt out of using their data for training[5]. Still, since they stopped sharing their research a long time ago, it’s impossible to know for sure how they build their models and to what extent user data is involved.
Self-improving myth
People who distrust OpenAI completely can argue that ChatGPT learns over time from users’ conversations, and when it generates text it can tell whether it saw or generated it before. In reality, that’s not easily doable. OpenAI for sure uses all the data it can get to improve the model, but not by just feeding it any nonsense users provide.

Let’s take Microsoft’s chatbot called Tay[6] as an example. Released on Twitter in 2016, it quickly became toxic after users reinforced her with a lot of unsavory messages. If OpenAI did the same, their model would quickly become useless or could even get hacked to do someone else’s bidding.
Lossy compression of training data
Last but not least, the way LLMs absorb knowledge during training doesn’t necessarily guarantee remembering that knowledge later. You can think of it as a lossy compression algorithm - similar to the way your images, if stored as JPEGs, irreversibly lose their quality - the model tries to condense the data. Only in this case, it’s not as much about reducing the data size, but about learning some generally useful capabilities and concepts out of it. Each example fed to the model makes it more probable the model will remember a given sequence or claim.
Summing up
As you can see, ChatGPT isn’t aware of its limitations and if improperly used it will go along with the prompt, producing misleading results:
- ChatGPT can blatantly lie, because it mocks the text it has been trained on (mostly internet) in a probabilistic fashion
- ChatGPT model probably hasn’t seen other users conversations, even if, it’s likely it wouldn’t remember them word for word
So the answer “Yes it was me” was the most likely completion for the given prompt, not the most truthful one. It’s based on nothing more than just probabilities encoded in the model.
This example shows that using ChatGPT might sometimes require some deeper knowledge of how GPT models really work under the hood. In any case, probably a good rule of thumb: don’t ask ChatGPT questions you don’t know the answers to or which you cannot verify.
Sources:
[1] https://openai.com/blog/chatgpt
[2] https://openai.com/research/instruction-following
[3] https://twitter.com/sama/status/1631002519311888385
[4] https://techcrunch.com/2023/03/01/addressing-criticism-openai-will-no-longer-use-customer-data-to-train-its-models-by-default
[5] https://openai.com/blog/new-ways-to-manage-your-data-in-chatgpt
[6] https://en.wikipedia.org/wiki/Tay_(chatbot)