AutoGPT is not using vector databases anymore 🙅
This might come off as a surprise to some. From the very beginning vector databases were supposed to help manage the long-term memory of AI agents.
What happened with the original idea? What has changed?
Let’s start with some context and how AutoGPT came to be.
AutoGPT’s vision
AutoGPT’s release on March 30th marked a peak of ChatGPT hype.
It is one of the most notable AI projects that sparked developers imagination on how LLMs such as ChatGPT could be used to create fully autonomous agents working on complex tasks.
Instead of prompting the model over and over again, an autonomous agent could work on its own, planning tasks, dividing them into smaller ones and executing the full idea.
Plans were ambitious. Proponents presented a complex architecture based on LLMs as the reasoning engine, separate part focused on planning, task management & prioritization. The idea included a way to manage agent’s memories in the form of embeddings and a vector database to store those and retrieve when needed.
Hence, it seemed at the time that vector databases were considered to be an important part of the whole solution. Other AGI projects were adopting the same approach too, e.g. BabyAGI[1].
Going to AutoGPT’s documentation[2] now, we might encounter a very surprising warning message:

It turns out AutoGPT recently went through “vector memory revamp” (pull request) that removed all vector db implementations and left out only a couple of classes responsible for memory management, with a JSON file becoming the default way to store memories/embeddings.
An Overkill Solution
Jina.AI founder, Han Xiao, once criticized original AutoGPT’s choice in his article[3], calling vector databases ”an overkill solution“.
The observation is actually very simple:
Let’s say LLM needs 10 seconds to generate a completion - that’s a single new memory to be stored.
You get to 100k memories after: 100 000 * 10s = 1 000 000s ≈ 11.57 days
Now that you have 100k embeddings even using the simplest brute-force algorithm, Numpy’s dot query, takes just milliseconds - the optimization is totally not worth it!
You don’t need an approximate nearest neighbors search, let alone vector databases.
Dot product’s inefficiency might become an issue only after a month of running AutoGPT and spending tens of thousands of dollars:
| Embeddings (AutoGPT calls) | Numpy’s dot product | AutoGPT inference | AutoGPT cost |
|---|---|---|---|
| 1 | <1ms | 10 s | $0.27 |
| 10000 | <10ms | 27 hours | $2,700 |
| 100000 | 70ms | 11 days | $27,000 |
| 300000 | 200ms | 34 days | $81,000 |
| 500000 | 5s | 56 days | $135,000 |
| 1000000 | 25s | 115 days | $270,000 |
| 2000000 | 95s | 231 days | $540,000 |
np.dot() run on 2019 MacBook Pro, AutoGPT’s cost assumes GPT-4 8K, single inference’s output = 1 embedding
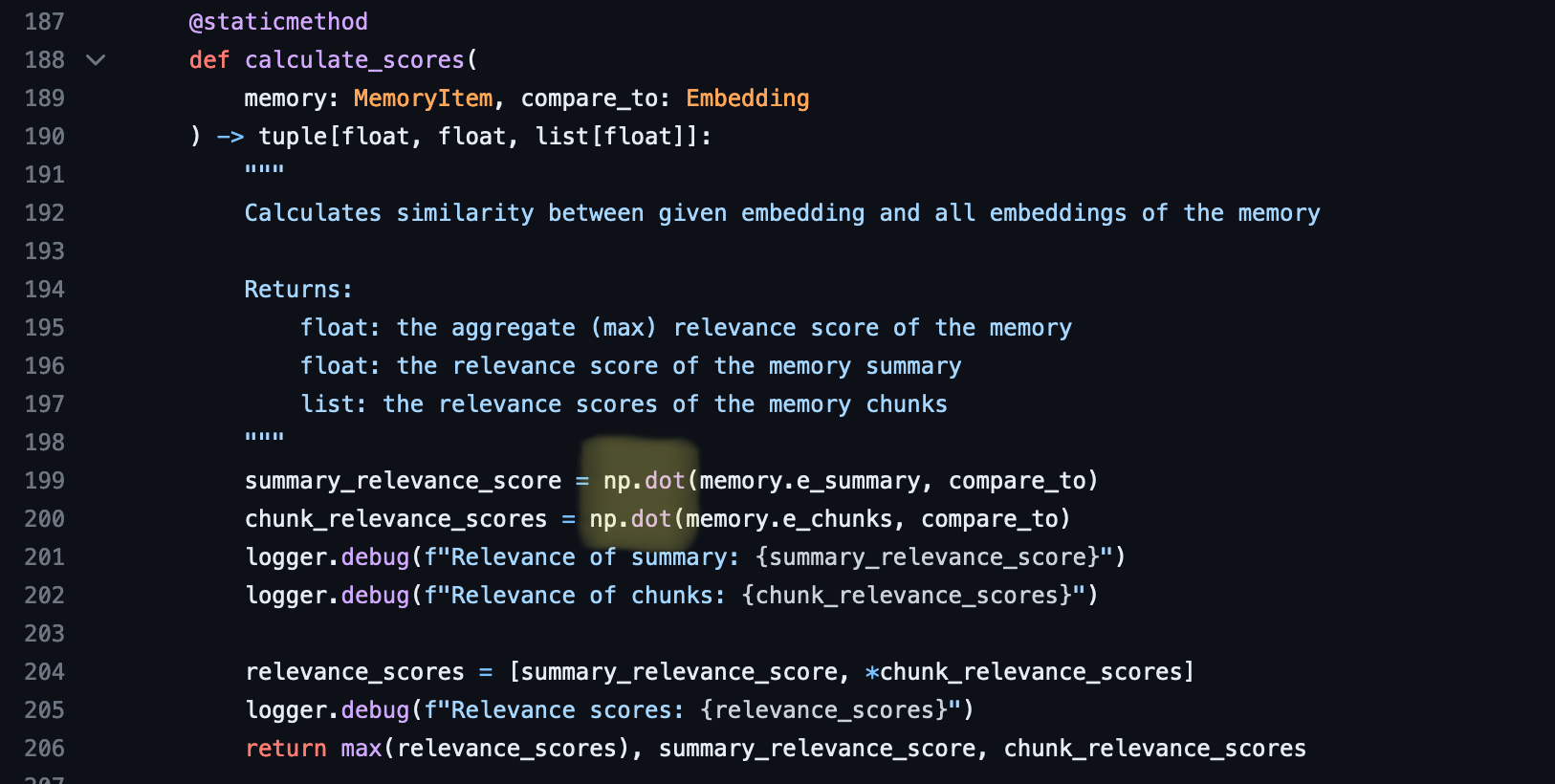
And it’s actually what we see in AutoGPT project right now: embeddings are compared using np.dot:
There’s an ongoing discussion[4] about bringing vector databases back and the authors mention that it’s not their priority at the moment, especially that they don’t see any added value.

Overengineering
We, engineers, naturally react to hype. We get obsessed with the idea of learning something new and building complex, all-powerful solutions. No surprise, AutoGPT included vector db at the very beginning. But as the time goes by, good engineers focus on what’s really important. Hype is over, now that some value needs to be delivered to the actual users, complexity becomes our enemy.
Multi-agent collaboration
There is another big shift happening right now towards having multiple agents, highly specialized, task-oriented, with their own memories and responsibilities, cooperating together.
As it turns out, a one-size-fits-all-tasks approach - having a single omniscient agent doing all the work - is not performing well enough.
Task-oriented agent can be given the examples of a certain task and via in-context learning it will naturally perform better. It will also limit the length of the prompt - it’s been recently proven LLM has a tendency to ignore stuff in the middle of the prompt[5].
Example workflow
An example of the multi-agent approach might be GPT Pilot. It aims at creating multiple agents corresponding to known roles across software development companies: product owner, developer, DevOps, architect etc. Here are the steps GPT Pilot takes to create an app:
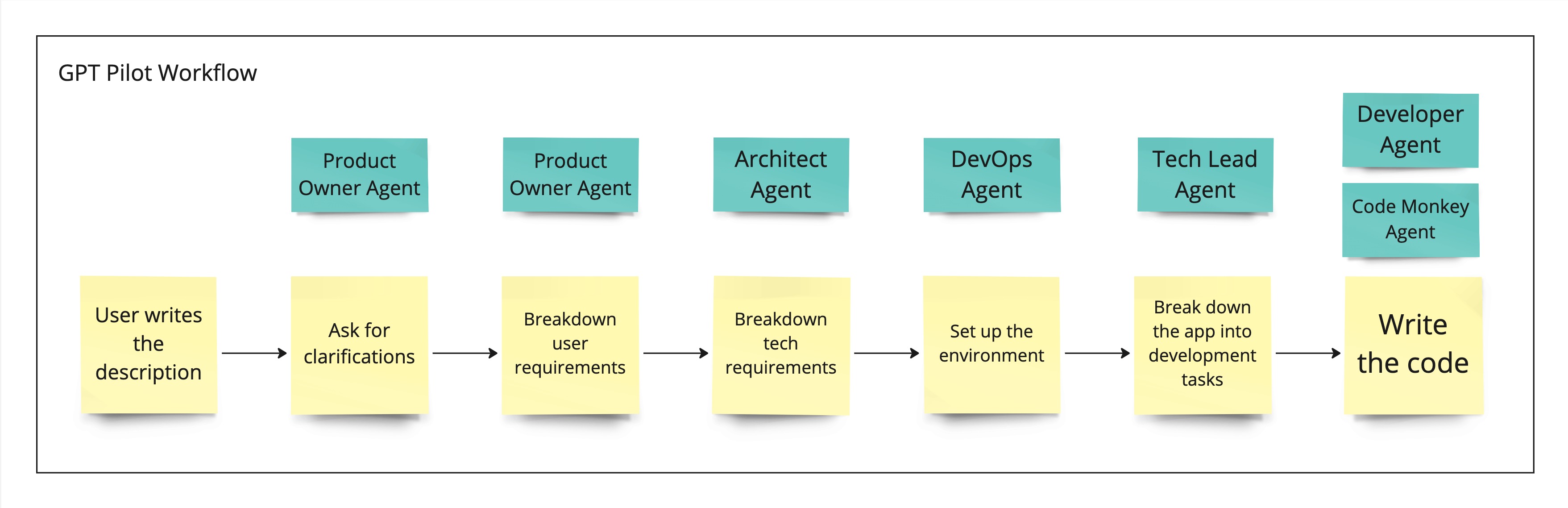
GPT Pilot also doesn’t use any vector databases. Coding tools often use different tools to get the relevant context instead, for example GitHub Copilot’s algorithm “looks” at the code from the recently used files or open tabs.
Looking at the problem a bit differently, these are the 2 options available for AutoGPT-like projects:
- a general-purpose agent with its thoughts being replaced for every different task
- highly specialized agents with their own short log of memories, specific for a given task
The second option seems to be more likely to have a higher accuracy at a given task than the generalist agent. The prompt with its identity can also have more precise description of how he should approach the problem.
Search agent
Autonomous agents have the capability to use various tools that we equip them with. They can use Google to find some relevant information on the web, they can use calculator or even write and execute code to solve a specific task.
Instead of fetching relevant memories, why don’t just use a normal search to find important stuff, previous notes? The search can be an abstraction, be either keyword search, vector or hybrid search - it doesn’t really matter. The important difference is that the agent can query it over and over again in different ways, until it finds whatever is needed or concludes the information is not there.
TL;DR
- AutoGPT’s decision to drop vector databases is a move in the right direction, to focus on delivering value instead of thinking about technology.
- Coding agents such as GPT Engineer, GPT Pilot, or even GitHub Copilot[6], don’t use vector databases - instead, they find relevant context based on file recency, proximity in the file system, or references to a given class or function.
- BabyAGI’s assumptions to store memories in vector dbs remained unchanged, but it seems like there aren’t many updates there and the original author decided to keep the algorithm simple as an example/foundation for other projects.
- Complexity is the worst enemy of a developer.
What’s to come
Will vector databases ever be brought back to AutoGPT?
Are vector databases actually an important part of AI revolution? Or will Pinecone’s vision to become a long-term memory for AI always be remembered as just an empty slogan?
Some argue the real issue is projects like AutoGPT don’t deliver any true value, and we’re still years away from such an idea becoming feasible.
Once again, seems like time will tell.
EDIT: 10/16/2023 - Added table with Numpy’s dot product benchmark along with AutoGPT cost and inference time
Sources:
[1] https://twitter.com/yoheinakajima/status/1642881722495954945
[2] https://docs.agpt.co/configuration/memory/
[3] https://jina.ai/news/auto-gpt-unmasked-hype-hard-truths-production-pitfalls/
[4] https://github.com/Significant-Gravitas/AutoGPT/discussions/4280
[5] https://arxiv.org/abs/2307.03172
[6] https://github.blog/2023-05-17-how-github-copilot-is-getting-better-at-understanding-your-code/
[7] https://github.com/Significant-Gravitas/AutoGPT/pull/4208
[8] https://lilianweng.github.io/posts/2023-06-23-agent/
[9] https://github.com/yoheinakajima/babyagi
[10] https://github.com/Pythagora-io/gpt-pilot
[11] https://github.com/AntonOsika/gpt-engineer